LSEG (formerly Refinitiv) is a world-leading provider of news content to the financial community. It is an American-British global provider of financial market data and infrastructure. The company was founded in 2018.
LSEG Real-Time Machine Readable News is the only low-latency, structured textual news service powered by Reuters. Reuters is the largest international news agency with more journalists in more countries than anyone else. Reuters has a long history of market-moving beats and exclusives related to macroeconomics, M&A activity, CEO changes, or corporate wrongdoing. Real-time News service delivers Reuters News unrivaled company, commodity, and economic stories formatted for automated consumption.
LSEG Workspace combines outstanding data, insider information, and comprehensive content coverage with cutting-edge online technology that is quick, simple, and logical. Students can progress their education, increase the depth of their comprehension, and effectively apply what they have learned by using workspace. Additionally, a built-in developer environment enables users to validate research and test ideas utilizing Refinitiv data, Python, and contemporary APIs.
Hanlon Financial Systems Labs aims at advancing student learning with market leading technology and data. Thus by providing access to financial data provided by the primary data providers in the fintech world, it presents a lucrative opportunity to students to explore broad and differentiated data sets in order to navigate the rapidly changing technological and financial markets.
To learn more about the LSEG news service, click here.
LSEG Data
LSEG offers one of the most comprehensive databases in the industry, covering over >85% of the global market cap, across more than 600 different ESG metrics, with a history going back to 2002. LSEG has data coverage for >12,000 global companies, across 76 countries, spanning major global and regional indices.
The data is provided in the following two formats:
- JSON format: This is the standard format provided by LSEG.
- PostgreSQL Database: This is the database server managed by the Hanlon Lab data team.
There are two ways to connect to the database server:
- One can connect to the database server from an individual computer.
- One can request a computing server which has faster network connection with the database server.
The database provides you with the headline, story body text and associated metadata about the news, which are dated from 1996 to now. You can also filter the news based on provider and company.
Stevens students can request access to a database on the Hanlon Lab PostgreSQL server and get the data yourself if you have prior experience working with SQL databases or can obtain Machine Readable News data by filling out the Google form in the link below.
User guide
- Fill in the Google form for requesting resources from the lab.
- While filling the form choose the appropriate option under "Category of Your Request".
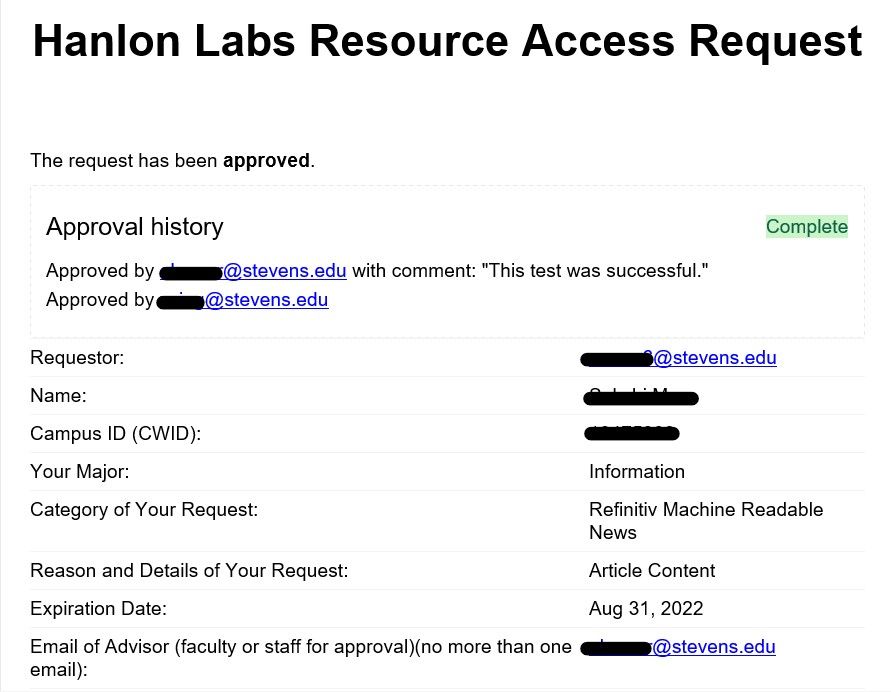
- Once the request is approved you will be emailed a "request approved" confirmation as shown in the picture 1.1
- A Hanlon faculty member will create unique credentials for the requesting individual in order to access the data.
- After gaining access to the database, the data can be downloaded as a CSV file.
About the Dataset
If you choose to export the dataset and work on it with python, please choose the correct delimiter when exporting the csv file. For example, if we choose the delimiter "|", it should be specified on the read_csv command.
import pandas as pd
data_frame = pd.read_csv("news.csv", delimiter = "|")
In the Hanlon Lab PostgreSQL machine_readable_news dataset contains primarily five tables data_audience, data_instance_of, data_subject, item_data, item_timestamp. These tables are shown in the screenshot below from pgAdmin.

Data field description
The fields that are primarily important throughout the database are listed below:
Guid: This is a globally unique identifier for the data item. All messages for this data will have equal GUID values and is present in all the tables.
Audience: This refers to product codes that identify which news products the news items belong to. They are typically tailored to a specific audience.
Example: "M" for Money International news, "FB" for French General News Service. These values are prefixed by "NP".
Instanceof: The named item codes are recurring report codes; they identify news items that follow a pattern or share the same code over periodic updates to the same subject matter and often have similar headlines. There are two topic code schemas - (N2000 codes and RSC codes)
Example: Under N2000 codes "L" for news on UK stocks, prefixed by "NI" . Under RSC codes "1200" for news on UK stocks, prefixed by "RR"
Subject: These identify under topic codes that describe the news items' subject matter. They can cover asset classes, geographies, events, industries/sectors and other types. There are two topic code schemas - (N2000 codes and RSC codes)
Example: Under N2000 codes "CDV" for credit default swaps, prefixed by "N2" . Under RSC codes "CDV" for credit default swaps, no prefixes.
Timestamp: There are two types of timestamps. Start: Represents the start of data archive. End: Represents the end of data archive.
To extract data from any one of these tables, you can run SQL queries in the "Query Tool" in pgAdmin. A simple query is shown below that returns all of the columns for the first 10 rows from item_data table.
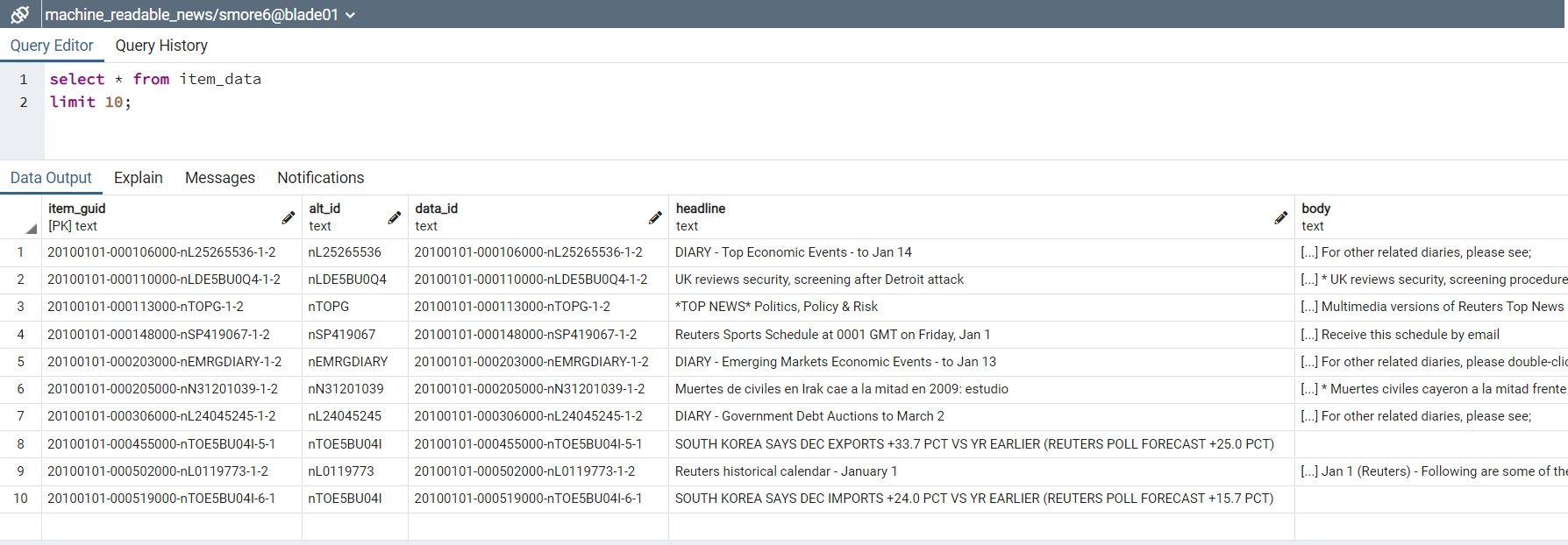
All tables contain three basic columns: id, item_guid and third column is the description specific for that table. (Ex. data_instance_of table consists of instance_of column)
The item_data table contains thirteen additional columns apart from the above mentioned. It is a detailed table describing data, its status and the type.
1. alt_id: It is the alternate identification number which carries additional associated information
2. headline: It is the most essential information relating to an emerging story.
3. body: It consists of the initial textual piece of the story, also known as the story body.
4. first_created: It records a creation date and time of a story.
5. version_created: It records a particular alert's date and time on a the story.
6. mime_type: It describes the types of the text, example plain/text gives a fixed width font.
7. pub_status: It gives the publication status, whether the data content is usable or cancelled.
8. item_language: It denotes the language in which the data item is present in, example "en" is specified for English language.
9. provider: It identifies the source that provided the news item.
10. take_sequence: The number of the news item, starting at 1. For a given story, alerts and articles have separate sequences.
12. message_type: It describes what type of a message would it be. It can be an - alert, first take subsequent take, correction, corrected, update, deletion.
13. urgency: It differentiates story types: 1 denotes Alert, 3 denotes Article. (Alerts are headline only messages and articles are messages that include a story body)
The item_timestamp table also contains columns apart from id, item_guid that give a detailed description with regards to the timestamp.
1. source: It is an identifier for the source from where the data originates, example EMEA and AMER denotes EMEA region and Americas region respectively.
2. timestamp_name: It denotes the types of timestamp, whether it is "recorded" or not.
3. timestamp_at: It records the timestamp along wth the timezone
For any questions or concerns, please contact us at fscadmin@stevens.edu.