Abstract
The primary goal of this project is to develop a model to help predict probability of the next non-S&P 500 Company to become a part of the index. The S&P 500 is widely regarded as the best single gauge of large-cap U.S. equities and has become the performance benchmark for U.S. equities markets. Investors and funds routinely buy and sell stocks in members of companies of S&P 500 and if the investors knew how the stock prices of additions and deletions are in the S&P 500 then they could make profits by investing into the respective stocks.
We aim to predict the set of companies that could be added to or deleted from the S&P 500 index to gain profit from taking positions in these companies before the announcement of the constituents. We first study the set of criteria on which S&P selection committee makes the decision on changing the index components. This helps us in deciding what set of factors need to be considered in the historical data set. Russell 3000 companies are considered for the input set. To replicate the selection committee's decision criteria, we consider a number of machine learning algorithms and generate predictions. Based on how accurately the algorithms predict the additions and deletions, we choose Random Forest as our primary model. We then propose ways to improve the model performance through parameter selection and the importance of each feature in the historical data.

Researchers:
Research Group (2015 Fall):
Pallavi Priya, Master in Financial Engineering, Graduated in Jan. 2016
Xueyang Ma, Master in Financial Engineering, Graduated in Jan. 2016
Advisor:
Dave O’Donovan, Accenture
Research Topics:
S&P 500, Russell 3000, Random Forest
Main Results:
The data set for which we performed predictions was of the third quarter of 2015. We chose the Russell 3000 September 2015 entries and using our trained model predicted the labels representing S&P 500 entries for October 2015. Once the predicted labels are obtained for October 2015, we compare the predicted and actual S&P 500 members for October 2015 with that of July 2015. The members that were present in July 2015 but are no longer available in October 2015 data set are marked deleted, while the members that are present in October 2015 but not in July are marked added.
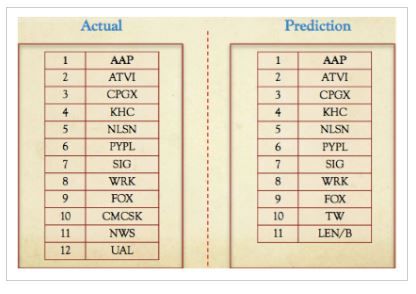
Additions
When October 2015 data set was compared with that of July 2015, there were actual 12 additions in reality while the model predicted 9 out of 12 additions correctly with 2 wrong predictions.
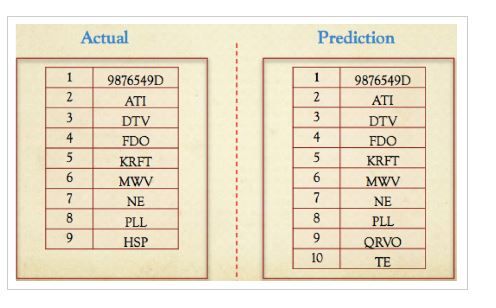
Deletion
The deletions are an important part of investment as the investor could take short position in the going to be deleted companies. In our project, we had 9 actual deletions and our model predicted 8 out 9 deletions correctly and 2 wrong predictions.
Conclusions
The model that we developed in this project has successfully captured the movements within the S&P 500 index with a high accuracy. This model shall serve as a helpful tool to make decisions in taking trading positions for investors