Researchers
Thomas Cifelli Jr
Lucas Fan
Alexander Galli
Faculty Advisors
Dan Wang
Dr. Zhenyu Cui
Abstract
Although there is research done before on credit rating prediction capabilites of corporations, it is mainly focused on using financial statements of companies which are mostly filed once in every three months. Worldwide markets are changing and operating on daily basis. So this prediction done every three months may not be relevant as soon as a couple weeks in the future. This project focuses on prediction of default probabilites everyday using textual data. It specifically does the sentiment analysis to understand if it can be a useful variable to predict default probabilties. The research done by authors concludes that sentiment just by itself does not yeild very accurate predictions, but when it is combined with daily financial data, the predicitions are improved providing a foundation for future research towards using public sentiment to predict daily default probabilites.
Modeling
Step 1 - The Sentiment Index
To utilize sentiment scores effectively in a time series model with sporadic tweet data, "Sentiment Index" was impemented. This index calculates the average daily sentiment, incorporating it into the previous day's index value with a specified decay factor. This decay accounts for the diminishing impact of older information over time, maintaining sensitivity to new data. This approach transforms sentiment into a continuous variable, facilitating its integration into time series modeling.
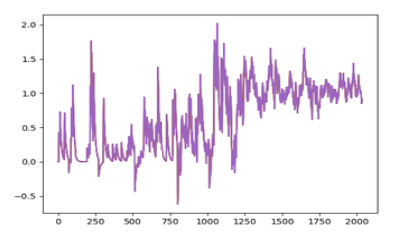
Step 2 - Initial Modeling with William's Company
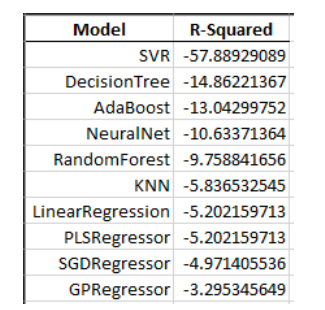
William's Company (ticker WMB), part of the S&P500 energy sector, displayed an unusually high number of credit events, totaling ten changes since 2015 during the five-year analysis. Despite being an outlier, the hope was that initial models could decipher the underlying causes of these events and apply this knowledge to other companies. Various regression-based models, such as Decision Tree, Ada Boost, Random Forest, and more, were employed using the sklearn package in Python. These models initially used the sentiment index as the input variable and Bloomberg's One-Year Daily Default Probability as the target variable. However, the results were notably poor, with negative R-Squared values, prompting the need for an alternative approach.
Step 3 - Switching to Tesla Motors
The decision to shift focus to Tesla was primarily driven by its significantly higher popularity and visibility. Tesla's widespread recognition, linked to Elon Musk's actions and the company's public prominence, allowed for the collection of a much larger dataset (1.65 million tweets compared to 35 thousand for William's Company). This shift aligns with the project's core objective of examining the influence of public sentiment on default probability. Despite still obtaining subpar results, even the best-performing models showed slight improvements over those for William's Company. This prompted consideration of a new approach called multivariate modeling.
Step 4 - Multivate Modeling
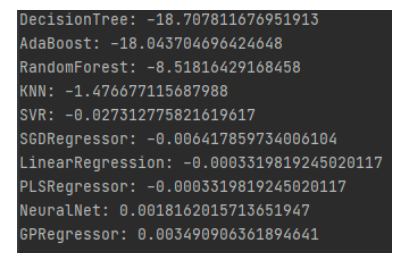
Initially, models focused solely on the relationship between the sentiment index and default probabilities as a single input variable. Since the univariate results were underwhelming, it was decided to explore the possibility that combining sentiment with other financial metrics could improve model performance. Authors incorporated daily log returns, daily CDS spreads, and the daily price-to-sales ratio into their models. Subsequent results with this multivariate approach were as follows:
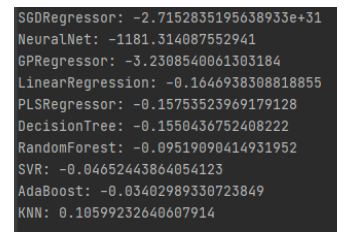
The results appear similar to previous ones, but the K-Nearest-Neighbors regressor achieved an R-Squared of over 0.1, marking a significant improvement. However, it remains uncertain whether this improvement is solely due to the inclusion of new variables or the combined effect of sentiment data and new variables, necessitating further testing by running models with the sentiment data removed for comparison.
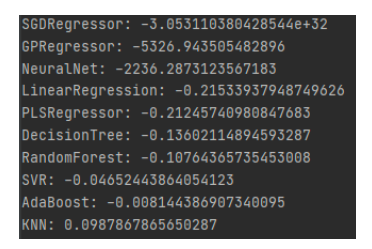
A notable improvement was observed when the sentiment data was included, with the K-Nearest-Neighbors model achieving an R-Squared of 0.106 compared to 0.0988 without it, signifying a 7% enhancement in model performance.
Results
In summary, the study has limitations due to time constraints and a focus on a limited dataset. The results with Tesla suggest that if sentiment has a significant relationship with financial data and default probability, it appears to be parametric in nature. Among the various models tested, only the K-Nearest-Neighbors (KNN), a purely non-parametric model, showed promising results, possibly because sentiment's influence is non-linear, which other models couldn't capture. The Neural Net's failure to exhibit similar improvements might be attributed to its default settings not being optimized for non-parametric performance. While a definitive conclusion could not be drawn, these preliminary findings open doors for future research to explore the implications further and verify the hypothesis on a broader scale.
Conclusion
In conclusion, the findings suggest a potential non-parametric relationship between public sentiment, particularly from sources like Twitter, and specific financial fundamentals, including Bloomberg's Daily One-Year Default Probabilities, especially for widely discussed companies like Tesla. Although the results do not conclusively confirm this claim, the authors believe thier research provides a foundation for future studies to build upon and either validate or refute the findings. Authors anticipate further advancements in this area of research.