Researchers:
Jimit Sanghvi
Yi Rong
Jingbo Xu
Faculty Advisors:
Dr. Ionut Florescu
Dr. Gary Englar
Abstract:
Quantitative Finance (QF) is the interdisciplinary field between Mathematics and Finance. Using machine learning methods to identify structural and content patterns in research articles of QF would be very important for researchers to really know how different fields contribute the interdisciplinary. It can go even further on the subcategory of quantitative finance. Two main techniques are applied for this purpose: supervised learning with deep learning models to classify research articles in the domain of Quantitative Finance, and unsupervised learning with Latent Dirichlet Allocation (LDA) for detecting themes without preset categories. The aim is to determine the mathematical or financial orientation of papers, ensure category names' consistency across various sources, uncover the relationship between content and subcategories of QF and reveal hidden topics within these domains. The results are expected to improve the understanding and classification of interdisciplinary research within QF.
Methodology:
1)Data Engineering
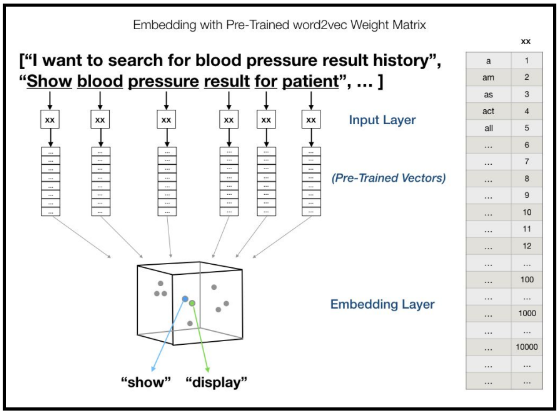
Research papers from the fields of Finance, Mathematics, and QF are obtained using web scraping techniques in Python from databases such as arXiv and SSRN. A total of 50,000 papers are compiled, with challenges arising in converting these PDF documents into a text format suitable for analysis. This conversion process is complicated by various "noises" such as non-text elements and non-ASCII characters. Non-ASCII characters are filtered out using the Unicode data python package. Punctuation and common words that don't contribute to semantic analysis, known as stop words, are removed using the Natural Language Toolkit (NLTK). The pre-processing steps include tokenization, which breaks the text into manageable pieces, and the creation of 2-gram and 3-gram models to predict sequences of words. Lemmatization is applied to reduce words to their base or dictionary form. The Word2Vec model is then used to assign numerical values to each word, which helps in the subsequent supervised and unsupervised learning phases. For this, two resources are utilized: TensorFlow's dictionary, which includes 80,000 words, and spaCy, a pre-trained model that assigns 300 numbers to each word. After these steps, the data is clean and ready for machine learning analysis.
2) Artificial Neural Networks
A Summary Presentation of Neural Networks in Application is shown in Fig. 2 below:
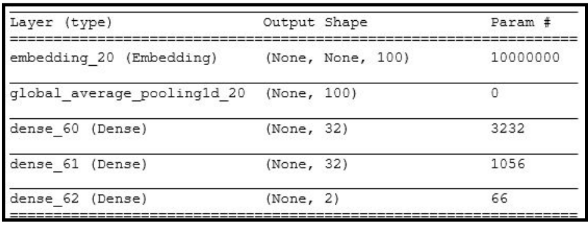
The input of this model is a matrix, in which there are 8000 columns for each row. The input layer uses an embedding layer to convert integers representing words into fixed-size vectors.
The hidden layer employs global average pooling to condense the feature map and ReLU activation functions within its perceptrons. Output layer utilizes the softmax activation function to classify outputs based on predefined labels. An 'Adam' optimizer for iterative weight updates during training is also employed. A categorical cross-entropy loss function is used to measure the model's performance.
3) Latent Dirichlet Allocation
Unsupervised learning algorithms, such as Latent Dirichlet Allocation (LDA), are employed to infer patterns from datasets without labeled responses, particularly useful in text mining. LDA is utilized to classify large volumes of text documents by identifying a set of topics, which are distributions of words that appear in statistically significant ways. In this approach, documents are considered mixtures of various topics. LDA helps in revealing sub-topics within domains such as Mathematics and Finance by representing documents as probabilities over a set of topics. This enables each research paper to be characterized by a specific mixture of topic distributions, thus uncovering the hidden thematic structures within the corpus.
To apply LDA in classification, the research papers are first randomly divided into training and testing sets. LDA is then used to cluster the document corpus into two distinct topics, corresponding to the two domains of Mathematics and Finance. The dominant topic for each document in the testing set is determined using the model, and the majority rule is applied to label each topic as either Mathematics or Finance. The effectiveness of this classification is measured by comparing the model's topic assignments with the actual domains of the papers in the testing set, thereby calculating the model's accuracy.
Results:
Part 1: Supervised Learning
1) Domain Classification with supervised learning
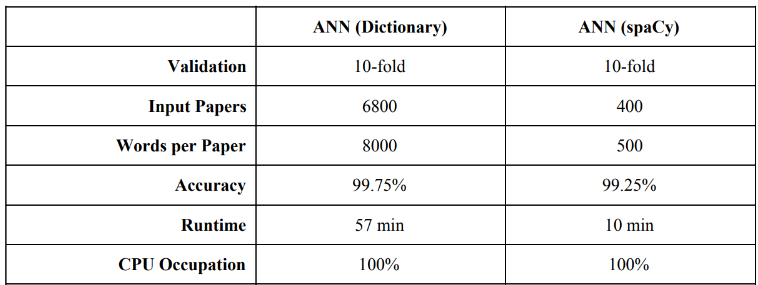
Three key assumptions were tested for the supervised learning approach: differentiable patterns between math and finance papers, patterns defined by effective words excluding symbols and numbers, and the feasibility of machine-based classification. Two methods were employed on a dataset of 6800 papers: the 'Dictionary' method, which created a numeric matrix representation of words, and the 'spaCy' method, which used a 3-dimensional array based on part-of-speech features. The classification accuracy of both methods exceeded 99%, confirming the initial assumptions and demonstrating that machines can effectively differentiate between mathematical and financial research patterns.
2) Pattern Distribution of Quantitative Finance Papers
The model quantifies each paper's relevance to math or finance, where a combined score of 1 represents a balance. Scores near 1 indicate a math focus, while scores near -1 suggest a finance focus. After evaluating 3697 papers, the findings revealed a majority (56.6%) favor math over finance (43.4%).
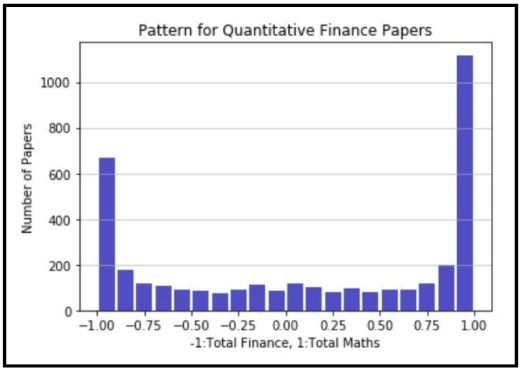
3) Pattern Distribution of Two Same-name Categories
The study investigated whether two identically named categories from different sources, "Financial Network" from SSRN and "General Finance" from ArXiv, represent the same type of research. After analyzing 200 finance papers from each source, the results suggested a discrepancy. ArXiv papers were more math-oriented than those from SSRN, challenging the assumption that identical category names across sources imply similar research content. This disparity also sheds light on why "General Finance" is considered a subcategory of quantitative finance on ArXiv.
4) Pattern Distribution of Subcategories in Quantitative Finance
In analyzing the pattern distribution within ArXiv's quantitative finance subcategories, the study sorts them into three groups. The first group, including Mathematical and Computational Finance, predominantly features mathematical patterns, with over 60% of papers skewed towards math. This finding is intuitive given the mathematical focus of these areas.
Conversely, the second group is characterized by a finance-dominant pattern, notably in Statistical Finance, suggesting the model may not accurately distinguish between related disciplines like economics or physics. The third group shows a balanced mix of math and finance patterns, evident in subcategories like Portfolio Management, Pricing of Securities, and Risk Management, reflecting their interdisciplinary nature.
Part 2: Unsupervised Learning
1) Domain Classification with Un-Supervised Learning (LDA)
LDA was used to categorize 6800 research papers into two topics, intuitively corresponding to Finance and Mathematics based on content analysis. Documents in the test set were then labeled according to the majority presence of words associated with each topic, aligning with human interpretation. The model's performance was evaluated against the true labels of the test documents, showcasing a high accuracy rate of 99%, with precision, recall, and f1-scores also at 99%. This demonstrates that the LDA model is highly effective at classifying papers into the correct domain, with most papers in the test set being classified with over 90% probability to their respective topics. The results affirm the model's significant accuracy in distinguishing between Mathematics and Finance papers without prior labeling.
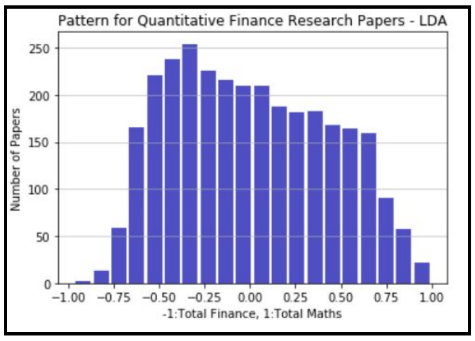
2) Pattern Distribution of Quantitative Finance Papers
For the pattern distribution in QF papers, the LDA model was utilized similarly to the approach in supervised learning. The distribution, as depicted in the results, indicates that the majority of Quantitative Finance papers have a 30% to 70% probability of aligning with either Mathematics or Finance. This suggests a significant overlap and interdependence between the two disciplines within the field of Quantitative Finance.
3) Pattern Distribution of Subcategories in Quantitative Finance
Applying the LDA model to 200 papers each from seven subcategories of QF demonstrated varying degrees of overlap between Mathematics and Finance. Computational Finance, Portfolio Management, Risk Management, and Pricing of Securities subcategories showed a substantial blend of both disciplines, with no single domain dominating. Notably, around two-thirds of the papers in these subcategories presented a balanced mix of mathematical and financial concepts.
In contrast, Mathematical Finance papers were heavily skewed towards Mathematics, with about 95% focusing on mathematical theories or a combination of math and finance. Similarly, papers on Trading and Market Microstructure, as well as Statistical Finance, were primarily finance-oriented. These patterns highlight the model's capability to discern the interdisciplinary nature of Quantitative Finance and suggest that a more specialized model trained on domain-specific papers could provide deeper insights.
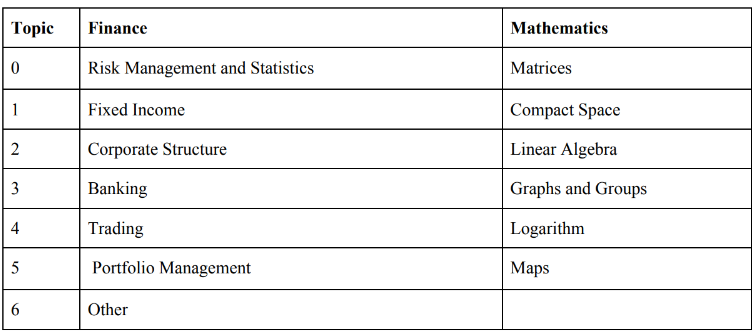
4) Topics in Mathematics and Finance domain
The LDA model was used to extract unique topics from research papers in the Mathematics and Finance domains, aiming to delve into the specific abstract topics discussed within these fields. A key aspect of this process was determining the optimal number of topics, which was achieved by calculating coherence scores. The optimal number of topics was found to be 7 for Finance and 6 for Mathematics, with the distribution of words across these topics illustrated in their respective domains.
The Finance LDA model successfully identified clear and recognizable topics within the Finance domain. The topics within the Mathematics domain, while distinct, were not as immediately recognizable, indicating that a more refined dataset and improved data cleaning methods could enhance the model's performance in identifying topics.
Conclusion:
Above all, the supervised i.e. ANN learning models can show the clear pattern of papers, either Math, Finance or Mixed. The same-name categories from different sources would have different paper patterns. Subcategory of quantitative finance do influence research pattern. With the unsupervised approach i.e. LDA, how the papers are distributed is more clear. We have a better idea of what the papers are talking about and find the hidden information. Based on the results, we can clearly see that the pattern of paper are various and some papers do not exactly follow the
common sense of those fields.