Abstract
Credit rating analysis has been a challenging topic over recent years because it is a crucial indicator of the debt issuer's ability to make the repayment of interest and principal payments. Thus, to know the credit rating would be really important. We implemented a deep neural network aiming to replicate the S&P's rating of technology companies based on the assumption that there is a relationship between the company's financial metrics and its ratings.
To obtain 20 basic financial metrics and the corresponding credit rating of various firms (from the same industry) divide into a training set, a validation set and a testing set. Using the financial metrics as inputs of ANN to predicate the credit ratings and find the relationship between financial factors and credit ratings. The prediction accuracy of credit rating prediction model is 80%. The model will be analyzed by different methods, including different nodes, different hidden layers, dropout method, and different methods of feature selections, to find the closet model with rating agencies used and the best model to predict the rating values.
Research Topics:
Artificial Neural Network, Cross-Validation, Credit Rating
Researchers:
Jie Shen, Master in Financial Engineering, Graduated in May. 2018
Guhao Sun, Master in Financial Engineering, Graduated in May. 2018
Yunying Wang, Master in Financial Engineering, Graduated in May. 2018
Youjia Yan, Master in Financial Engineering, Graduated in May. 2018
Advisor
Dr. Pape Ndiaye
Main Results:
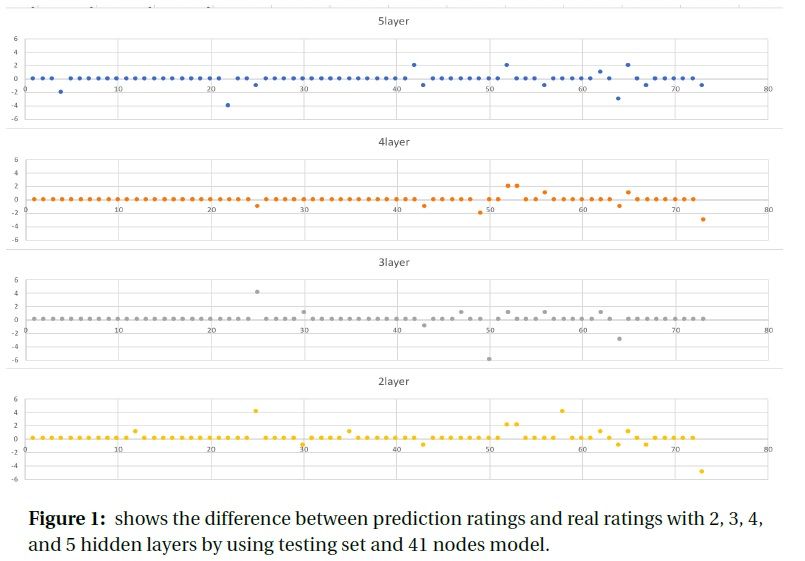
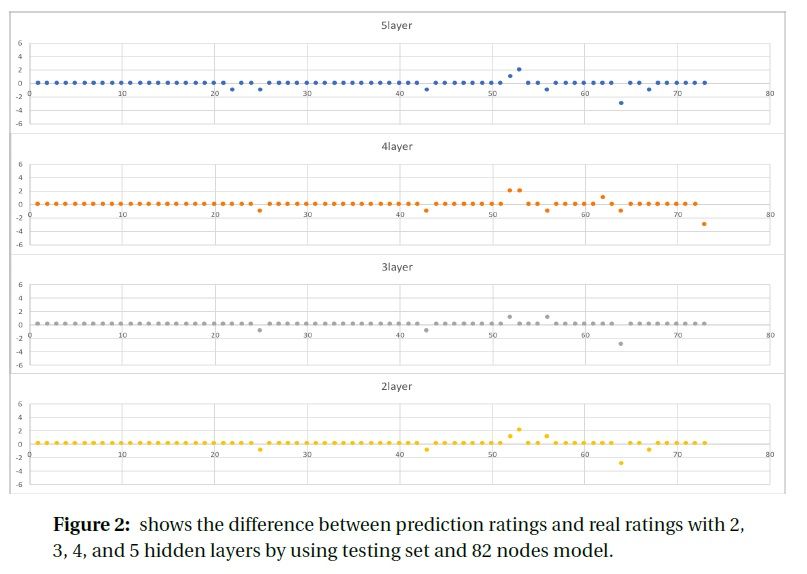
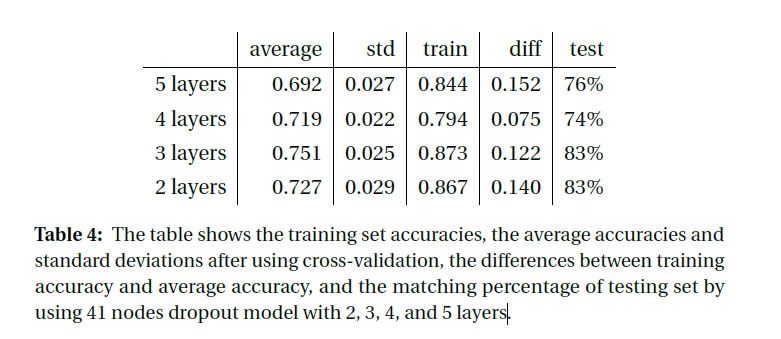
As shown in Figure 6a, Figure 6b and Table 2, we can easily get the percentage of matching ratings between real and prediction. Using 41 nodes, the matching percentage is 84%, 88%, 88%, and 82% for 2, 3, 4, and 5 hidden layers. So, the 3-hidden-layer and 4-hidden-layer have the best testing results. Same fore 82 nodes, the 3-hidden-layer has the highest matching percentage. Thus, the results shown above verifies our conclusion that the 3-hidden-layer is the best model structure in our project.

Conclusions:
Based on the model setup and improvement, the best model structure for our project is the Artificial Neural Network model with 3 hidden layers and 164 nodes in each layer. The accuracy is around 80%. For over-fitting solving, we used three methods, dropout, feature selection, and early stopping.
Dropout technique is reducing over-fitting problem but the accuracy is decreasing a little. ANOVA selection method improve the model and increase the accuracy but do not help a lot with over-fitting problem. Early stopping reduce over-fitting problem but sacrifice the accuracy that the accuracy decrease a lot compare with other results.
Thus, above all the models and testings we try, the ANN model we have to predict the credit rating is success that the accuracy is high enough for prediction. For over-fitting problem, people need to consider their own situation because sometimes the accuracy is important sometimes the fitting level is important. To sum up, choosing different methods to solve the over-fitting problem in different situation is the best way to find your own model.