Author:
Shenze Yu, M.S. in Financial Engineering, Graduated December 2019
Xinlei Liu, M.S. in Financial Engineering, Graduated December 2019
Advisor:
Dr. Ionut Florescu
Abstract
This paper implements genetic algorithm (GA) with classifiers support vector machine (SVM) and artificial neural network (ANN) to search optimal feature sets that could evaluate ratings. In this project, we use financial data of open companies in four sectors : energy, financial, healthcare and consumer discretionary. To investigate the feature learning capacity of genetic algorithm, the results are compared with results from convolutional neural network (CNN) and random forest (RF).
Keywords: Genetic Algorithm, Support Vector Machine, Artificial Neural Network, Convolutional Neural Network, Random Forest, Feature Selection, Credit Rating
Main Result:
We split our data sets into training, testing and validation data sets chronologically and implement four ways of feature selection to calculate the validation set accuracies.
For CNN, we used 1-D convolutional layer with 64 feature detectors (a kernel size of 3 applied to each feature detector). Also, another 1-D convolutional layer with 32 feature detectors (a kernel size of 3) will learn more complex features. To reduce further over-fitting, a drop layer is added, 40% of the neurons will be randomly set to 0. Finally, we added fully connected layer which uses a softmax activation function to produce a probability distribution over the 23 classes.
The original SVM was for binary classification only, so in order to do multi-classification, there are four typical methods we could use: one-vs-rest (OVR), one-vs-one (OVO), directed acyclic graph (DAG) and error correcting output codes (ECOC). We picked the one performed the best for our datasets, which is OVR.
Considering the complexity of ANN and the computational cost, we used 200 hidden layers each with 100 units. And we choose the solver ’adam’ (a stochastic gradient-based optimizer proposed by Kingma, Diederik, and Jimmy Ba) which performed the best for our datasets.
And Finally for RF, we know the more trees are added, the less likely the model overfits, we finally used 100 trees for each of our model considering computational cost.
The table below shows the details of our result.
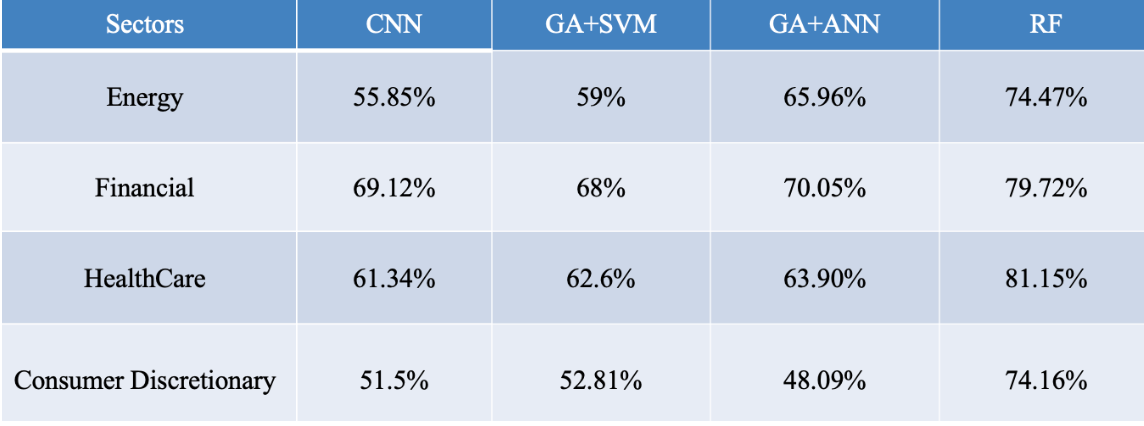
We find out that different models and different sectors have different sensitivities for features. However, our approach of using genetic algorithm is proved not a successful method. Random forest is a more powerful learning method for credit rating feature selection, which outperforms GA and CNN by 10% at least.
Conclusions:
Our goal is to test if genetic algorithm could outperform the existing method of feature selection and our algorithm indeed reduces the input dimensionality and increases accuracy to a great extent. But there are still more powerful feature selection learning models, like random forest, which is outperformed dealing with unbalanced and missing data.