Students in the Special Projects in Financial Analytics course recently presented their final projects, showcasing innovative applications of modeling, machine learning, and quantitative finance across various domains, including high-frequency trading, credit risk, portfolio management, and market microstructure. This was so impressive that I gave only A’s for the first time ever.
Agentic AI Trading Memory
Authored by Lauren Colasanti Advisor: Prof. Victoria Li
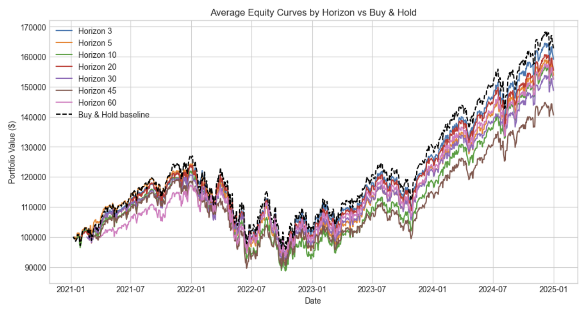
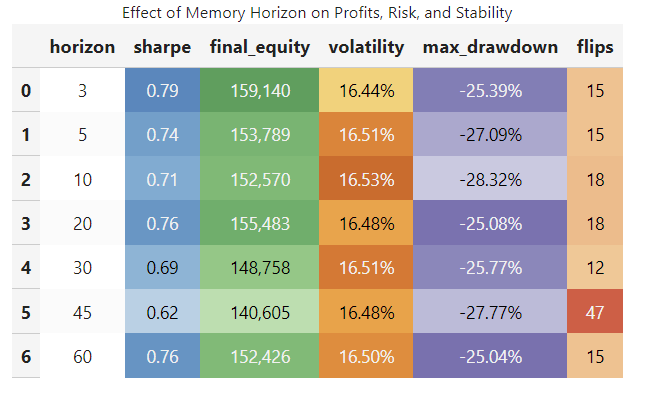
This project addressed how the memory horizon of an agentic AI affects its trading performance in the S&P 500 (SPY). The core problem was optimizing trading stability, volatility, and profitability rather than simply predicting prices. The methodology involved training agents using Proximal Policy Optimization (PPO) coupled with a small neural network. Data used spanned from 2015 to 2025, and performance was rigorously evaluated using stress testing (a synthetic 10% price shock) and regime analysis based on the VIX index. The primary contribution of the research was the finding that the most effective trading strategies lay at the extremes of memory horizons. Short horizons (3–5 days) were found to be agile and responsive, recovering quickly from shocks and excelling in fast-changing, volatile environments. Conversely, long horizons (45–60 days) emphasized stability and risk control, effectively limiting drawdowns, though overall equity accumulation was lower.
I/B/E/S EPS Forecasts
Authored by Nicholas Masi Advisor: Prof. Dragos Bozdog

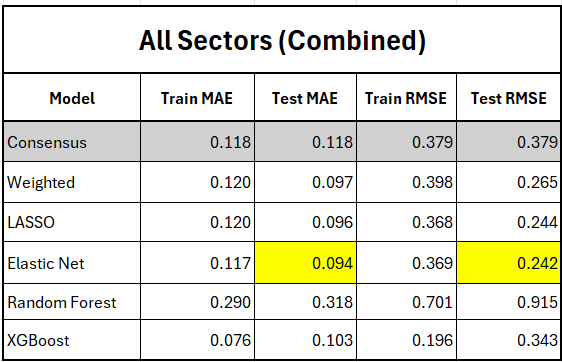
The goal of this project was to determine if machine learning (ML) models could surpass traditional analyst consensus forecasts in accurately predicting earnings per share (EPS), and whether incorporating analyst information could refine predictive accuracy. EPS forecasts are crucial for company valuation and trading strategies, but traditional consensus forecasts are not always optimal. The methodology involved comparing multiple models, including linear and tree-based methods (LASSO, Elastic Net, Random Forest, XGBoost), against the analyst consensus baseline across different industry sectors (e.g., Health, Tech, Energy, Industrial, Financial). The main contribution demonstrated that ML models consistently outperformed analyst consensus in most sectors. Specifically, regularized linear models, such as Elastic Net and LASSO, provided the best balance of stability and accuracy. Furthermore, factors reflecting analyst bias and dispersion were identified as highly impactful predictors, especially in stable sectors.
Does use of Alternative Data source generate incremental alpha in cross-sectional equity return prediction?
Authored by Satvik Gurjar Advisor: Prof. Zachary Feinstein and Prof. Majeed Simaan

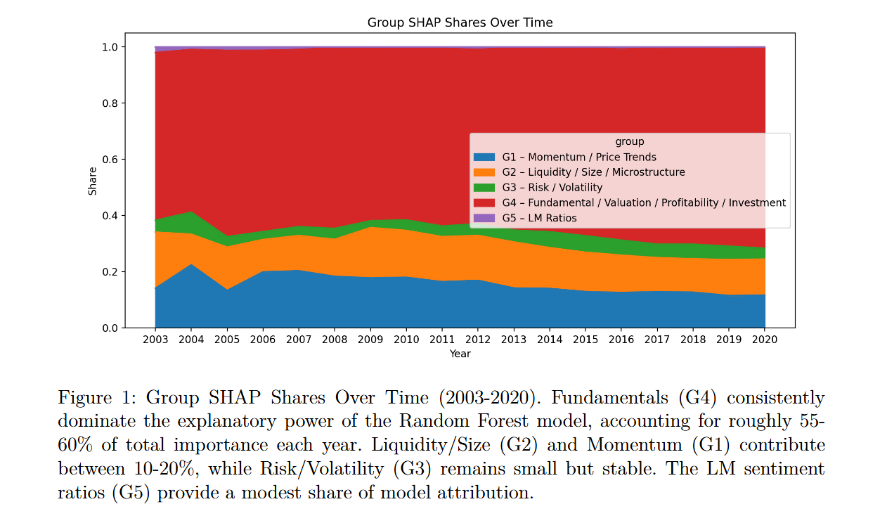
This project sought to determine whether utilizing alternative data sources generates incremental alpha in cross-sectional equity return prediction and explored the risks associated with integrating such data into quantitative models. While alternative data like textual disclosures and sentiment measures capture nuanced firm behavior, they also introduce challenges like data quality and model risk. The methodology established a benchmark using traditional models (OLS, Random Forest, Neural Networks) trained on 94 standard firm characteristics. Alternative data was introduced using Loughran-McDonald (LM) linguistic ratios derived from SEC EDGAR filings. The main finding was that language-based LM ratios provide complementary predictive information beyond standard firm characteristics. The economic relevance of these textual signals proved conditional on core firm characteristics such as size, value, risk, and volatility.
Implied Willow Tree for Treasury Futures
Authored by Sharif Haason Advisor: Prof. Zhenyu Cui

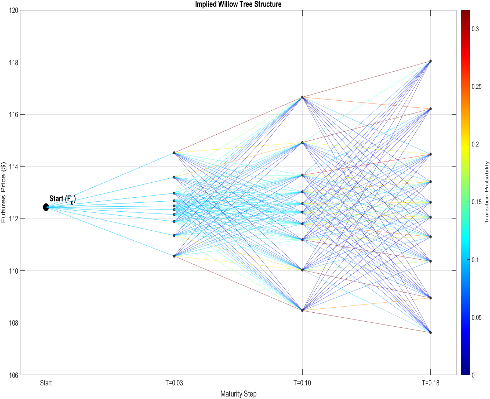
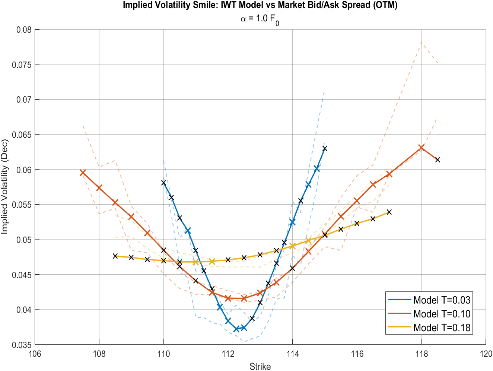
The project focused on applying the Implied Willow Tree (IWT) framework to calibrate and price derivatives on 10Y Treasury Futures. Traditional tree models often suffer from computational inefficiency and high model risk, prompting the use of the IWT, which models transitions between risk-neutral densities (RND). The methodology introduced by Dong et al. (2024) was used, involving four key steps: moment extraction from Out-of-the-Money (OTM) call/put options, transforming the normal distribution via the Johnson curve, solving for node probabilities, and generating the Transition Probability Matrix. The key contribution was successfully adapting the IWT framework to non-equity options (Treasury Futures) for pricing, demonstrating that the method can be calibrated using data from the highly liquid Treasury futures options market.
Regime Sense: Detecting and Forecasting Financial Market Regimes
Authored by Swapnil Pant & Swara Dave Faculty Mentor: Prof. Ionut Florescu

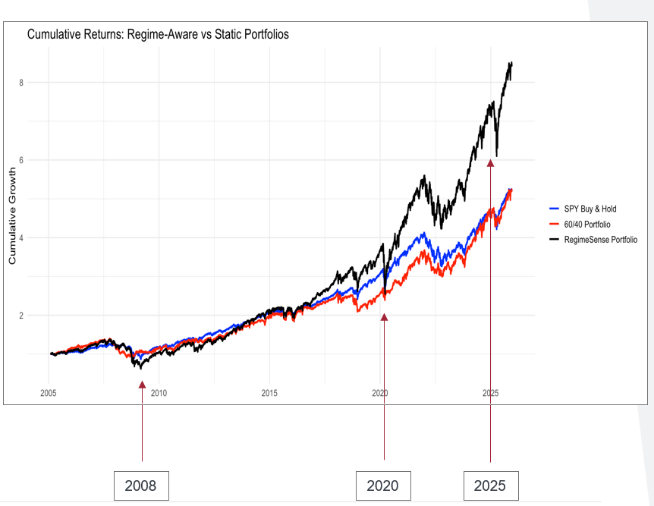
The central problem addressed was that market behavior shifts between distinct regimes, and ignoring these changes can lead to poor portfolio choices, especially during market stress. The researchers aimed to test whether regime-aware portfolio strategies could outperform static benchmarks by mitigating drawdowns. The methodology utilized Hidden Markov Models (HMM) to detect market regimes—classified as Calm, Neutral, or Turbulent—from market indicators like SPY returns, VIX volatility, and the term spread. A dynamic allocation strategy (RegimeSense), adjusting weights across equities (SPY), bonds (IEF), and gold (GLD) based on the inferred regime, was compared against Buy & Hold SPY and a Static 60/40 portfolio. The major contribution was demonstrating that the RegimeSense portfolio significantly reduced drawdowns during crisis periods (2008, 2020) compared to pure equity exposure, proving that regime awareness improves downside risk management and enhances portfolio resilience.

Fairness, Explainability (XAI) and Performance in Bank Account Fraud Detection
Authored by Akanksha Sharma Advisor: Prof. Dragos Bozdog

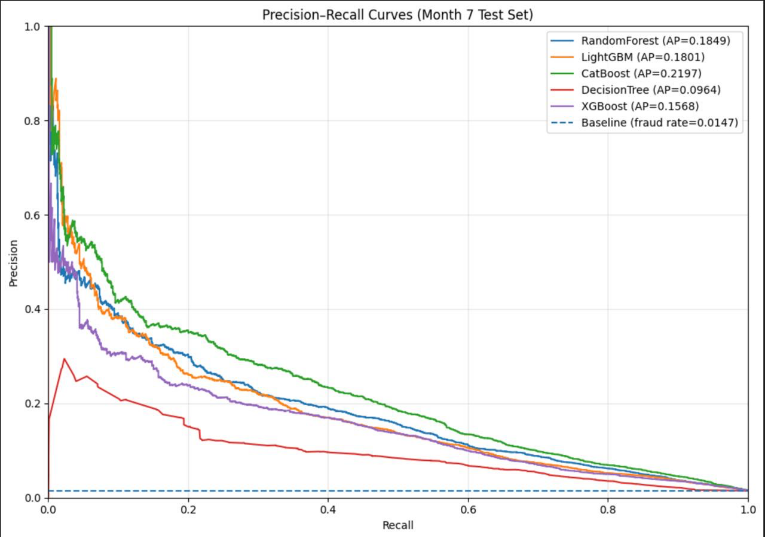
This project aimed to develop supervised machine learning models for bank account opening fraud detection that effectively balance high performance with crucial aspects of fairness and explainability. The problem is challenging due to the highly imbalanced nature of the data (only ~1% fraud rate) and the high costs associated with false alarms and fairness risks. The methodology explored multiple tree-based models (such as Random Forest, XGBoost, and CatBoost) and evaluated their performance based on recall at a targeted 5% False Positive Rate (FPR). The primary contribution was identifying CatBoost as the best-performing model for achieving the highest recall at the required FPR, suitable for operational deployment. Crucially, the fairness assessment revealed that legitimate customers over 50 years old faced disproportionately higher false alarm rates (4x higher than those $\le$50), highlighting that fairness issues arose from excess false positives rather than missed frauds.

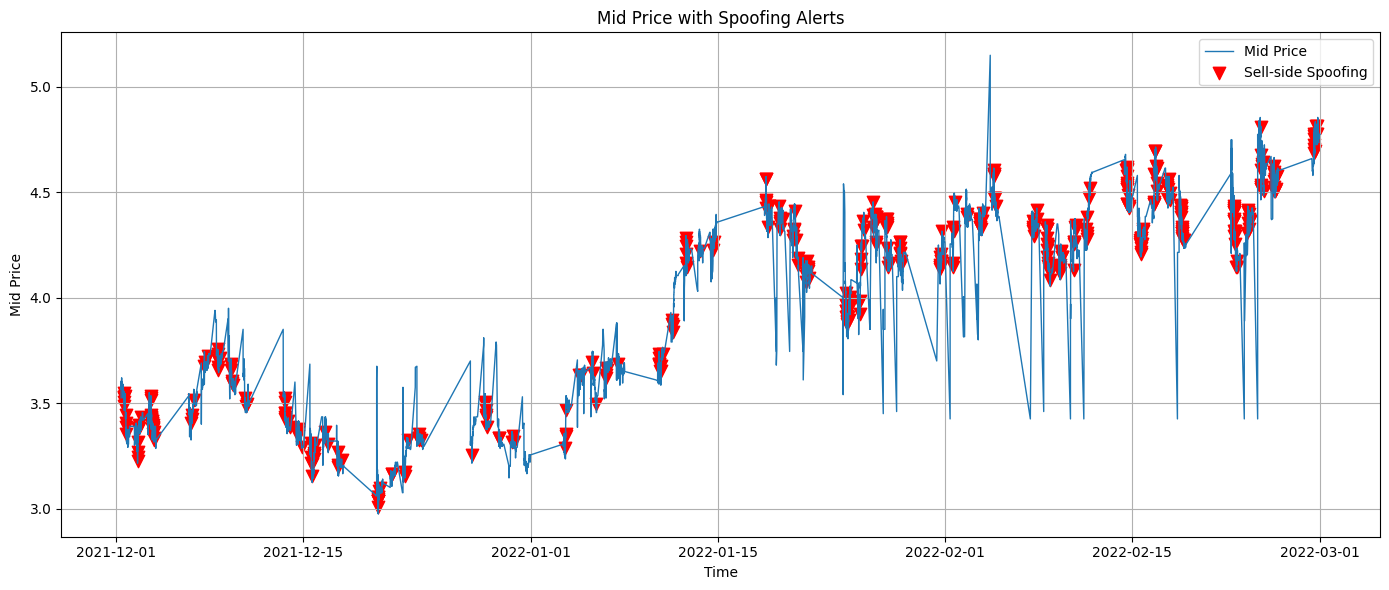
Spoofing
Authored by Xiao Jin Advisor: Prof. Steve Yang

The project investigated spoofing, a fraudulent trading practice defined by placing large, fake orders with no intention of execution to manipulate prices. Spoofing is a major concern for market integrity, often involving three steps: Build Up, Cancel, and Sweep. The methodology centered on detecting these activities by applying threshold-based metrics derived from the Limit Order Book (LOB), including High Quote Activity (HQA), Order Imbalance (UQ), Cancellation Activity (AC), and Mid-Price Change (MPC). Case studies were performed across diverse markets: WTI Crude Oil Futures (institutional), Game Stop (retail), and Cryptocurrency (frontier). A key insight was that spoofing behaviors are market-dependent, and the defined detection metrics perform best in liquid, regulated markets.
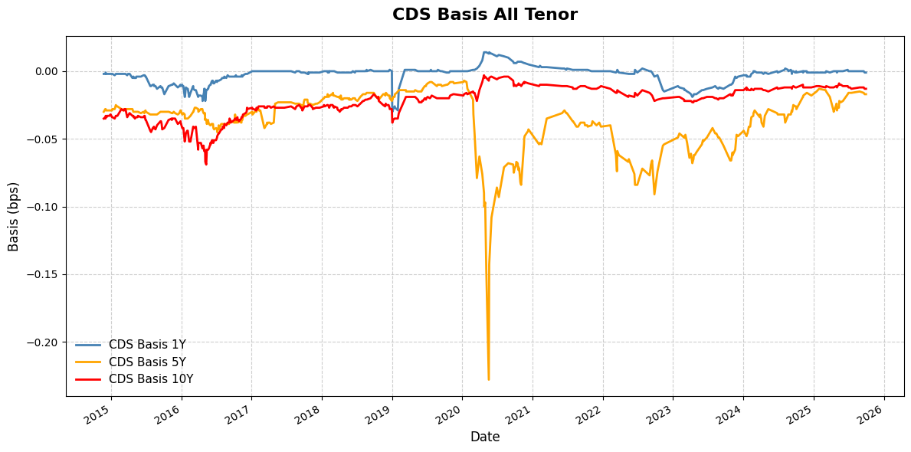
Corporate Bonds and Credit Risk Reduce Form Modeling
Authored by Anthony Giller and Liam Rodgers Advisor: Prof. Dragos Bozdog

The core objective of this research was to measure the consistency of issuer hazard rates derived from corporate bonds and Credit Default Swaps (CDSs), and to explore methods like Nelson-Siegel modeling for hazard rate interpolation. The problem involved defining and estimating credit term structures consistently across different financial products. The methodology employed a Reduced Form Modeling, or Survival-Based Framework, for bond pricing, using the Option Adjusted Spread to Fit (OASF) as an issue-specific discounting adjustment. They compared survival probability estimation techniques (Exponential Spline, Nelson-Siegel, Piecewise Spline, Cubic Spline) and utilized the resulting survival probabilities to calculate the CDS Bond Basis, revealing potential mispricing. A major contribution was showing that adopting the survival-based valuation method leads to a large decrease in the forecasted sensitivity to interest rates compared to conventional duration measures, particularly for distressed bonds.
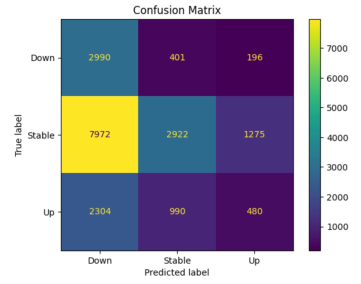
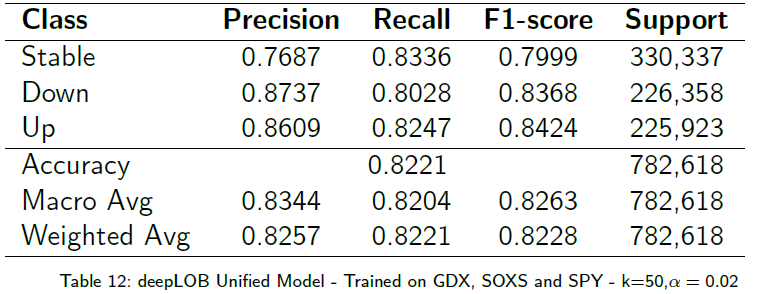
Deep Neural Network for Limit Order Books Forecasting
Authored by Naveen Nagarajan Advisor: Prof. Dragos Bozdog
This presentation focused on utilizing Deep Neural Networks (DNN) for Limit Order Books (LOB) forecasting, which is critical for generating trading signals in high-frequency trading (HFT) strategies. The prediction problem is complex due to the enormous amount of noisy, non-stationary data within the LOB. The research aimed to determine how well DNN models perform on LSEG Level II market data, assess the predictability of high-frequency mid-price changes, and explore the use of a single DNN model across multiple ETFs. The methodology involved studying two established deep learning models, CNN1 and deepLOB, using Level II market data for selected ETFs (GDXU, SOXS, and SPY). The models were trained to classify future mid-price movement (Up, Down, Stable) over short horizons (k=50, 75). The main contribution was demonstrating that the deepLOB model consistently outperformed the simpler CNN1 model, achieving a profitable backtesting simulation on the SOXS ETF. Initial exploration of a unified deepLOB model trained across multiple ETFs indicated potential for improved transfer learning performance by expanding the training data and incorporating a broader set of ETFs.
Mil, Your Friendly Financial Strategist
Authored by Jerome Doughty and Amod Lamichhane Advisor: Prof. Zonghao Yang
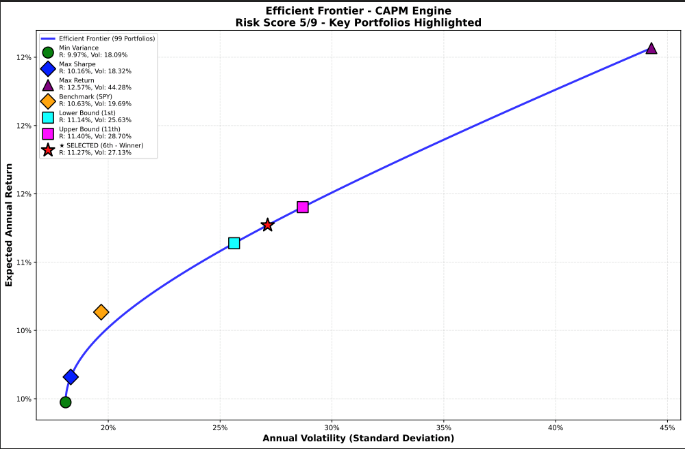
This project introduced "Mil, Your Friendly Financial Strategist," a dedicated, personalized future robo-advisor. The problem Mil addresses is the need to democratize financial investing for everyday people, improve financial literacy, and strengthen financial decision-making, utilizing the growing public acceptance of AI tools like robo-advisors. The methodology integrated several components: a 10-question interview to establish a Risk Profile (Risk Averse 1-3, Neutral 4-6, Seeking 7-9); data collection and feature engineering for 79 securities; three prediction models (CAPM, Elastic Net, LSTM) to generate expected returns; and Portfolio Optimization using Modern Portfolio Theory (MPT) to create efficient frontiers. The most critical step was the Arbiter Score (weighted 40% Financial, 40% Machine, 20% Backtest Score), which selected the optimal model for the user. The main contribution was creating a system where the backtested strategy consistently outperformed the S&P 500 (SPY) and a simple evenly weighted portfolio over 5, 10, and 25-year historical returns, with the overall goal of generating consistent, explainable results and building user confidence.
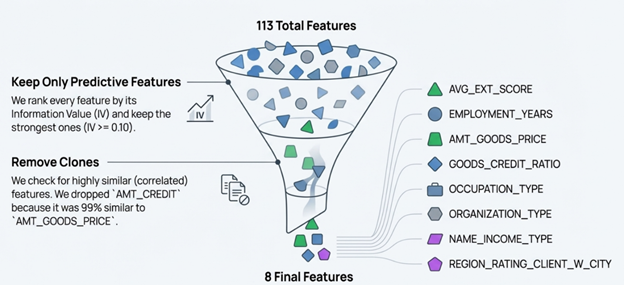
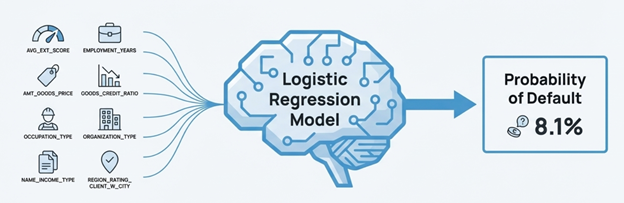
Credit Scorecard Development Home Credit Group
Authored by Veena Gorakanti Advisor: Dragos Bozdog

The project focused on the challenge of assessing risk for "Thin-File Applicants"—individuals with little or no credit history often excluded by traditional credit scoring systems like FICO. The main research question was how to build an interpretable credit scoring model to predict loan default probability for these individuals. The methodology utilized a highly imbalanced dataset (~307,000 loan applications with an 8.1% default rate) provided by Home Credit Group. Data preparation involved handling missing values, fixing anomalies, and feature engineering, culminating in the selection of 8 final features based on Information Value (IV). The model employed was a Logistic Regression model, chosen for its industry standard status and transparency, utilizing Weight of Evidence (WoE) to translate features into risk points. The main contribution was the successful construction of an interpretable credit risk scorecard, achieving strong risk separation (Test Gini: 46.8%). The model output was converted into a transparent points-based scorecard with clear risk tiers, showing a monotonic score-risk relationship, which is critical for supporting lending decisions.